AIOps 2.0: Zero-Touch Reliability
AIOps 2.0 is not just a tool—it is a managed outcome. It uses data such as metrics, logs, and traces to generate insights and predictions, which are then acted upon by LLM-driven agents through intelligent automation. The result is Zero-Touch Reliability across modern enterprise systems.
Service Overview
This service combines predictive observability, intelligent event management, autonomous remediation, and continuous optimization into a unified, self-improving operating model. It helps enterprises reduce downtime, eliminate alert fatigue, optimize cloud spend, and resolve incidents before users are impacted.
🔍 Predictive Observability & Analysis
- Full-Stack Pattern Recognition: Continuously ingests logs, metrics, and traces across hybrid environments to establish baseline behavior patterns.
- Anomaly & Drift Detection: Identifies subtle deviations in performance or configuration in real time, including configuration drift, before failures occur.
- Predictive Failure Forecasting: Machine learning models predict potential hardware or software failures such as disk exhaustion or memory leaks with a 24–48 hour lead time.
🧠 Intelligent Event Management
- Algorithmic Noise Reduction: Filters background noise and redundant alerts, typically reducing alert volume by 75–80%.
- Cross-Domain Event Correlation: Correlates alerts across network, database, and application layers into a single incident view for faster root cause identification.
- Service Impact Mapping: Connects infrastructure health to business services, ensuring mission-critical applications are prioritized during remediation.
⚙️ Autonomous Remediation
- Zero-Touch Incident Resolution: Triggers pre-validated automation scripts to resolve issues such as service restarts, cache clearing, and auto scaling.
- Closed-Loop Automation: The AI detects the fault, applies the fix, verifies the resolution, and updates the ticket. Humans are alerted only if the fix fails.
- Agentic Orchestration for Repair: LLM-powered agents reason through complex, multi-step recovery procedures across legacy and cloud systems.
📈 Continuous Optimization & SRE
- Adaptive Thresholding: Dynamically adjusts alert thresholds based on time, usage patterns, and historical trends.
- Root Cause Analysis Automation: Generates AI-driven RCA reports instantly, including long-term architectural recommendations.
- FinOps & Resource Right-Sizing: Continuously optimizes cloud resources based on real-time demand, reducing waste and lowering costs by 30–50%.
🤖 AI Models & Technologies
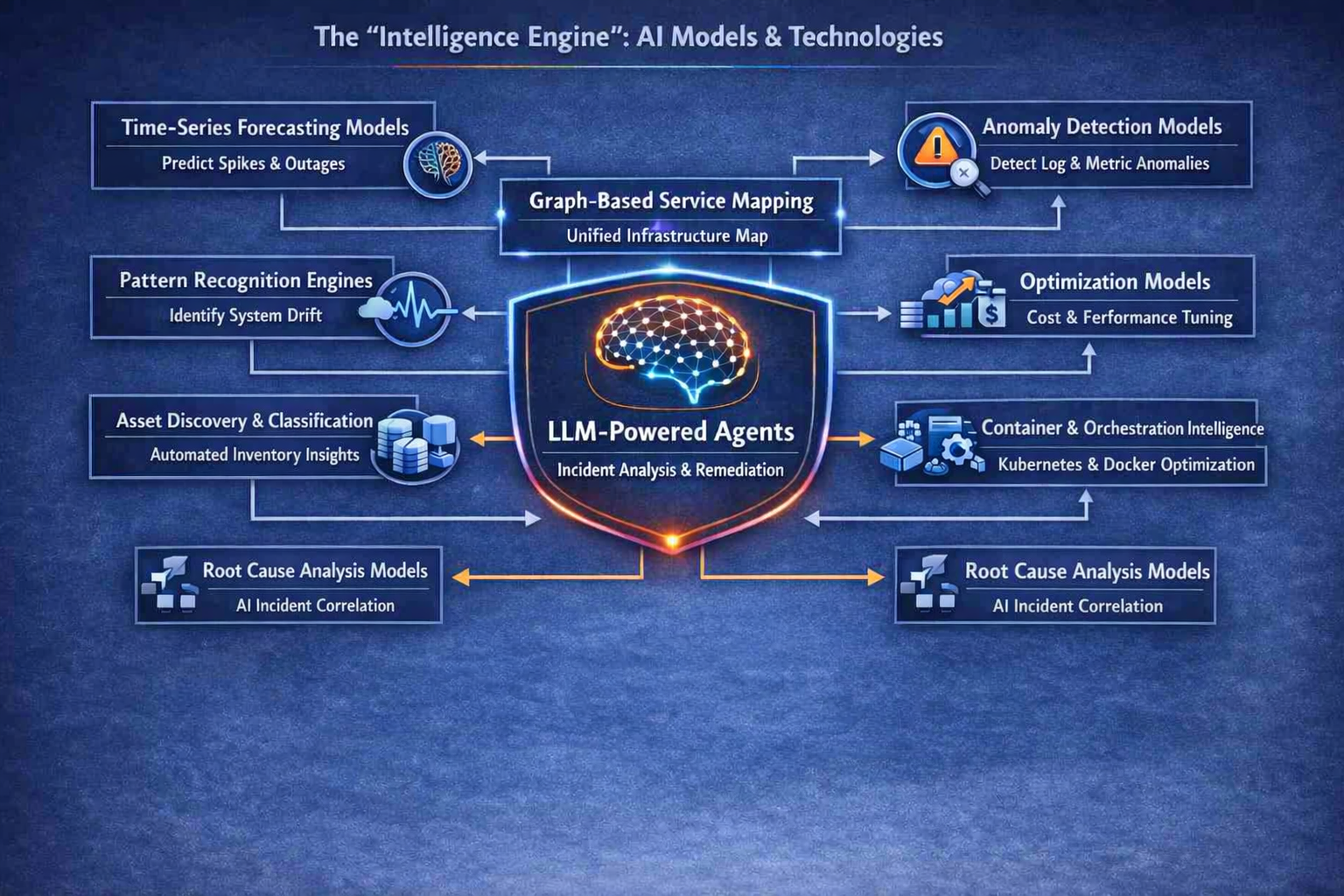
💼 Business Value
- Reduced Operational Noise: Minimizes alert fatigue, allowing teams to focus on high-impact issues.
- Faster Recovery: Improves mean time to detect (MTTD) and mean time to resolve (MTTR).
- Higher Uptime: Predictive and self-healing workflows significantly reduce service disruptions.
- Lower Cloud Costs: Intelligent scaling and resource optimization reduce unnecessary spending.
- Better Team Productivity: Engineers spend less time firefighting and more time on strategic improvements.
Managed Outcome
AIOps 2.0 leverages the data layer to collect metrics, logs, and traces, the insights layer to predict failures and identify patterns, and LLM-driven agents to execute remediation and optimization actions automatically. This creates a Zero-Touch Reliability model that enhances uptime, reduces operational noise, lowers cloud costs, and enables truly self-healing enterprise systems.
